
追加学習に設定した世界観を凝縮し(魔法名なども) AIにその町や村人を演じさせる事でそれなりの事ができるのではないかと思っているが この世界観設定を用意するのが大変だ。 どこかにそういう類のサンプルでも転がっていないだろうか…。 そこまでしたら、TRPGまがいな事も普通にできそうな気もする。 しかし別件もやっていて中々こちらは進んでいないが、いずれやってみる。
ざっくりと拡張方法を調べて行く。 https://note.com/doerstokyo_kb/n/n27092ccc720c この例では画像生成用のプロンプト生成となっているが(そういう使い方もあるか) 実行すべき世界観を用意する為にこういった追加学習は必要になるだろう。 現行の性能の高い学習モデルは実行にVRAMが43GBだったりと個人研究では難しい。 https://highreso.jp/edgehub/machinelearning/cyberagentllama31.html AIによってライター業が縮小するというのもあながち嘘では無いことが、触ってみると理解できる。 その気になればアフィリエイトサイトをAIで運営する事もできるだろう。 行きつく先は人の利権との衝突。 人同士ですら対立している現代なのにAIが認められて行くという事はないだろう。 (あなたの仕事を明日からAIにやらせますので解雇です言われて、ハイと言う人間は居ないので潜在的にAIは否定される) さあ、言語モデルでどこまでいけるのか。
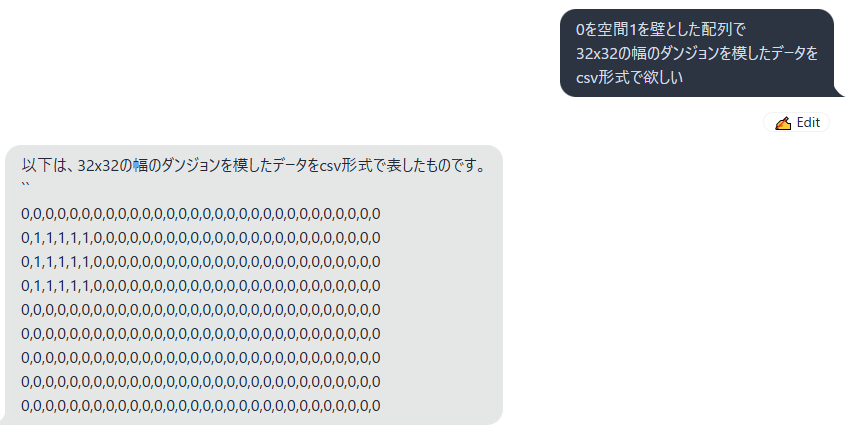 大体合っている!
だがソレじゃない…。
大体合っている!
だがソレじゃない…。
話は若干脱線。 AIはAIらしく画像生成での破綻もそうだったが 大規模言語モデルも同じようで、嘘が(破綻)が混じる。 パッと見でわかる画像と違い、情報のノイズは判断できる知識が無いと扱うのが難しい。
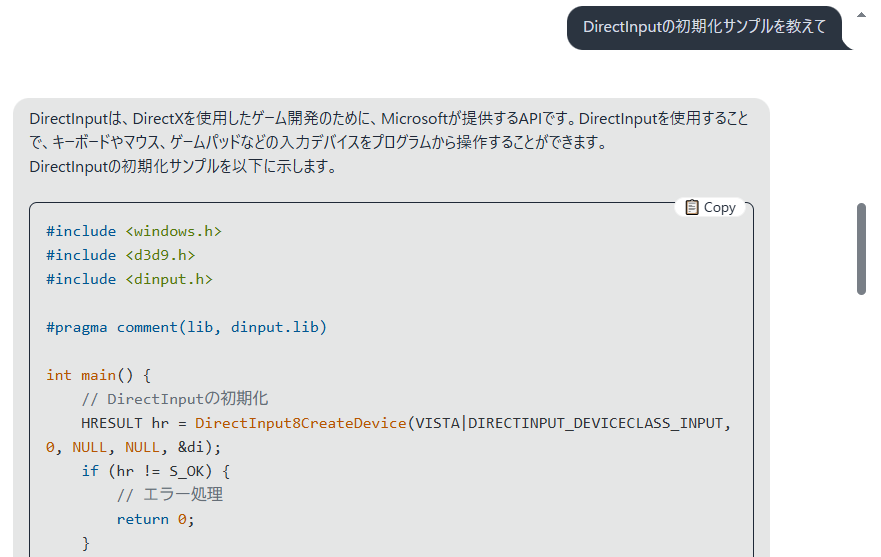 例えばこれも、とても有用であるが一発目から定義すらない変数を使っている。
当然コピペではエラーが起こるという訳だ。
大筋は当たっているが、嘘も混じっている
そんな感じなので、鵜呑みにするのは危険である事がよくわかる。
例えばこれも、とても有用であるが一発目から定義すらない変数を使っている。
当然コピペではエラーが起こるという訳だ。
大筋は当たっているが、嘘も混じっている
そんな感じなので、鵜呑みにするのは危険である事がよくわかる。
とりあえずllama.cppを使い、llama3モデルが実行できる環境まで辿り着いた。 さて、適当に何か言わせてみるとしよう。
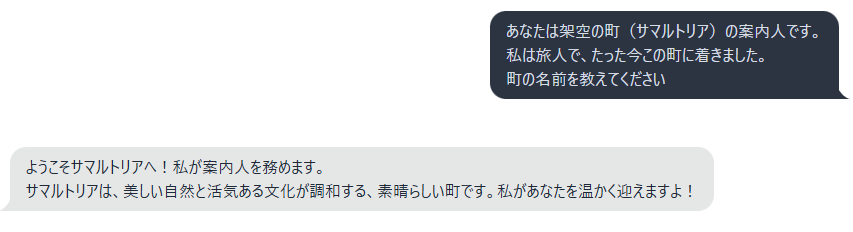 起動しただけで何の設定もしていないが…中々良い感じに動いてくれているようだ。
(画像生成AIと比べると凄い敷居の低さだ)
しかしLoraチューニングして行くには、かなりのVRAMが必要なので(無理)現段階では考えないでおくとしよう。
-------
GPUメモリ(VRAM)が23GBほど必要なため,
実行にはGPUメモリを増やすかモデルを量子化する必要があると思われる.
-------
https://zenn.dev/tasiten/articles/ccc6adad12f792
先駆者の軌跡を追う限り、チューニングしなくても設定を教える事で語尾を変えたり
Q&A方式でインプットするだけでも効果はあるようだ。
https://note.com/niki22mk2/n/nd269797a55cb
何か仮想世界を作りたくなった時にでも試してみるとしよう…。
起動しただけで何の設定もしていないが…中々良い感じに動いてくれているようだ。
(画像生成AIと比べると凄い敷居の低さだ)
しかしLoraチューニングして行くには、かなりのVRAMが必要なので(無理)現段階では考えないでおくとしよう。
-------
GPUメモリ(VRAM)が23GBほど必要なため,
実行にはGPUメモリを増やすかモデルを量子化する必要があると思われる.
-------
https://zenn.dev/tasiten/articles/ccc6adad12f792
先駆者の軌跡を追う限り、チューニングしなくても設定を教える事で語尾を変えたり
Q&A方式でインプットするだけでも効果はあるようだ。
https://note.com/niki22mk2/n/nd269797a55cb
何か仮想世界を作りたくなった時にでも試してみるとしよう…。
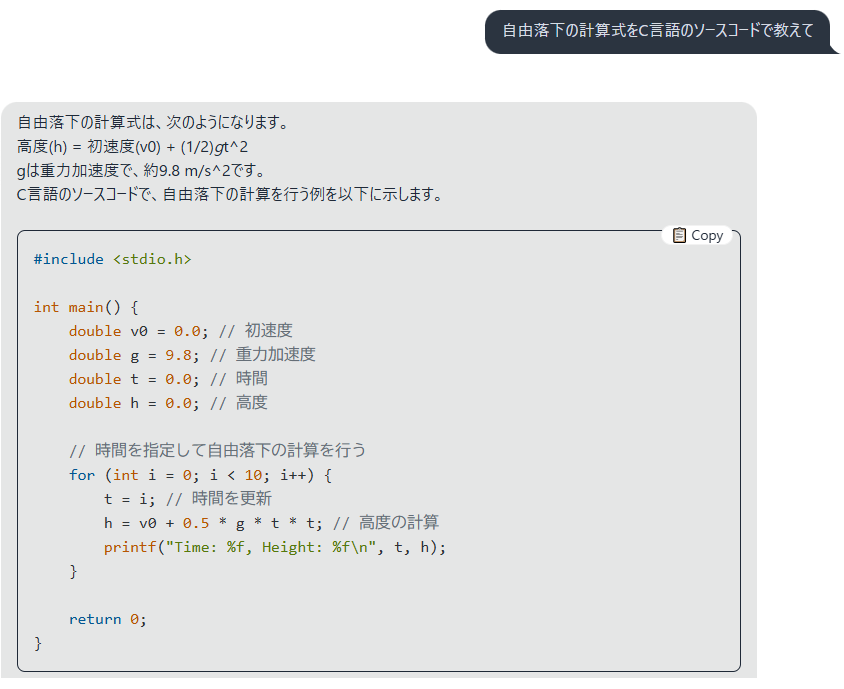 しかも普通に優秀なので諸々の開発に役立ってくれそうな勢いすらある。
本当に恐ろしい限りである。
しかも普通に優秀なので諸々の開発に役立ってくれそうな勢いすらある。
本当に恐ろしい限りである。
生成画像についてはおおよその感じが得られたように思う。 …次は言語モデルも触れてみたいと思います。 ChatGPTに性格付けや語尾付けなどを設定し 特定のキャラクターを演じさせて会話をするというものをローカルでやってみたいと考えている…が。 言語モデルに対し、架空の世界や町の設定を行い(設定ファイルを共通化しておく) 町の人の会話を大量に作らせよう…というようなもの。 これが上手く行くとして究極的にはゲーム本体と言語モデルを繋いでしまえば 町の名前を案内するだけのモブ会話もまた、無限のバリエーションで案内してくれるのではないか?というわけだ。 (ただし町の名前を案内するだけのモブで何十ギガと容量を食う) 現段階では漠然と、できるかもしれないな…程度の知識で挑むため 実際に上手く行かない壁もまたいっぱいあることが予測される。 まずは環境の用意からだが…。 ※これらの分野にも先駆者はたくさんいらっしゃるようで参考になりそうです。 https://seesaawiki.jp/chatgpt_char_prompt/d/%c8%c7%b8%a2%a5%ad%a5%e3%a5%e9
旧(主に画像生成)