
前回から年単位で間が空いた。 ニュース上のAIは追っていたが身辺が忙しく生成AIから離れていた。 その間に状況が様変わりしていたので現行最新の生成AIが集まるComfyUIを導入し暫く弄って居た。 なるほどこれは面白い。 ノードベースで繋ぐプログラム…さながらpython界のCFみたいなものだった 慣れるまでは大変だが慣れてくると色々と構築したくなるというもの。 例によってお題はゲーム用アニメーションデータだ 最近は動画生成AIもあるのでそれを使ってスプライトアニメーションも作ってみたりしたが ゲーム素材として見るとやはり今一つの出来になってしまう。 細部デザインの破綻は目をつぶったとしても中割コマの残像化など対処できない部分がどうしても出るのだ そもそも考えてみれば学習元の映像自体、動きのある物はブレて記録されているのだからブレているのが正解だ… 正解を再現してくれているんだからこれはもうどうしようもないのだ そこで今回考えたのはSpineだ 検出AIを組み合わせればその素材が上手く作れるのではないかという研究である (容量削減に破綻も無くなる一石二鳥) 問題はSpine素材を作り上げるまでの労力をどれだけ削減できるかである 今回主に使うのはPose Landmarkerとセグメンテーション検出 https://ai.google.dev/edge/mediapipe/solutions/vision/pose_landmarker https://ai.google.dev/edge/mediapipe/solutions/vision/image_segmenter Pose Landmarkerによって関節が検出できるというAIソリューションで
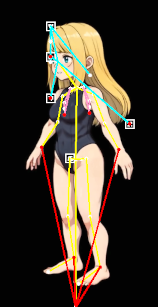
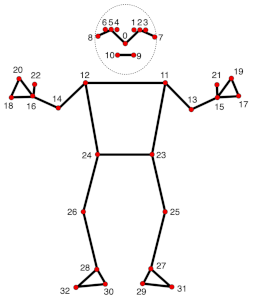 これの検出を画像に適用するとこんな感じに検出される
この時点で既にボーン情報が得られたと見ることが出来る
これの検出を画像に適用するとこんな感じに検出される
この時点で既にボーン情報が得られたと見ることが出来る



 (驚くべきは裏側にある構造の推測があり、映っていない腕の情報まである)
適当に動画化AIにアクションさせて検知
(驚くべきは裏側にある構造の推測があり、映っていない腕の情報まである)
適当に動画化AIにアクションさせて検知

 …お判りいただけただろうか。
座標差分を見れば既にアニメーションキーフレームが完成していることに!
…お判りいただけただろうか。
座標差分を見れば既にアニメーションキーフレームが完成していることに!
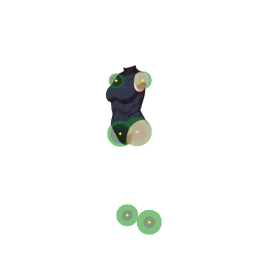
次に素材の切り出し 画像からパーツを切り出すだけだが、これは実に労力が掛かる。 ある程度はやむなしだが全部切り出すのはとても大変だ とにかくそこをどうにかしたい! プロトタイプとしてセグメンテーション判別とボーンの階層構造をjson出力するComfyUIワークフローを組んだ (残念ながらmediapipeによるセグメンテーション検出は実写学習モデルの為アニメ系には使えず)
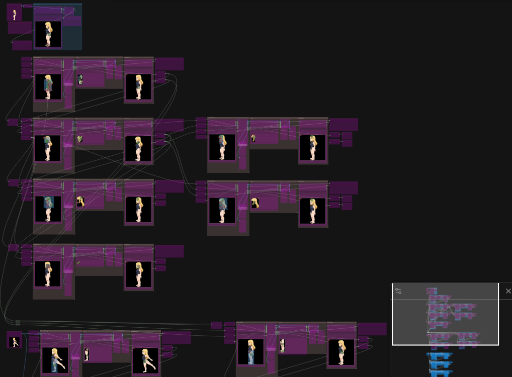 指定範囲を組んでSAMによる検出をUI化して繋ぎ込み、ボーン位置と連動させれば
必要な画像パーツのセグメント検出で自動的に切り抜くという代物だ…しかしこれでもノイズは混ざる
指定範囲を組んでSAMによる検出をUI化して繋ぎ込み、ボーン位置と連動させれば
必要な画像パーツのセグメント検出で自動的に切り抜くという代物だ…しかしこれでもノイズは混ざる
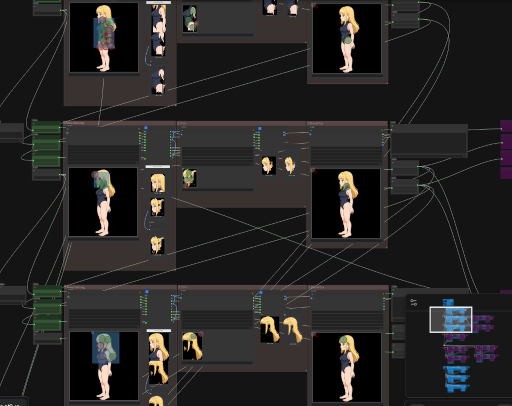 位置計算を挟みSpineの構成情報となるjsonを構築
位置計算を挟みSpineの構成情報となるjsonを構築
 最後はアレコレ手直し
最後はアレコレ手直し
 そしてプロトタイプ
う〜ん?
そしてプロトタイプ
う〜ん?
素材の切り出しをどうするかこねくり回していたが seethroughというlive2d切り出しモデルが最近出たらしい。
 セグメント検出の精度を上げる為に色付けしみたりしていたがAI学習には勝てませんね…
欠けてる部分の塗り直しもしなくて良くなるなんて…seethroughを試すことにする
ボーンについては親子構造に対しlengthを取り、atanで方向を合わせる
セグメント検出の精度を上げる為に色付けしみたりしていたがAI学習には勝てませんね…
欠けてる部分の塗り直しもしなくて良くなるなんて…seethroughを試すことにする
ボーンについては親子構造に対しlengthを取り、atanで方向を合わせる

 Spineのインポートフォーマットを調べ
頂点データからリグを自動で生成できるように調整
髪のボーンはARマーカーを使ってボーンになるように融合する
これなら3D人形でもARマーカーをテクスチャにするだけでモーションキャプチャが可能となる
ここにきてARが秘密兵器となった
で、一発ポンでリグ形成
Spineのインポートフォーマットを調べ
頂点データからリグを自動で生成できるように調整
髪のボーンはARマーカーを使ってボーンになるように融合する
これなら3D人形でもARマーカーをテクスチャにするだけでモーションキャプチャが可能となる
ここにきてARが秘密兵器となった
で、一発ポンでリグ形成
 IKも自動で埋め込み
AIにメッシュ割アルゴリズムを聞いたりしてメッシュ化
髪ボーンも自動で物理が効くように調整
IKも自動で埋め込み
AIにメッシュ割アルゴリズムを聞いたりしてメッシュ化
髪ボーンも自動で物理が効くように調整
 バラのパーツを調整するのがなんだかんだ大変なので
少しでも楽になるようにボーン情報を基点にピクセルの重なりを調べ
関節部に必要な塗り直しガイドラインを自動生成
透かして塗り込むだけで良くなり凄く楽になった…
バラのパーツを調整するのがなんだかんだ大変なので
少しでも楽になるようにボーン情報を基点にピクセルの重なりを調べ
関節部に必要な塗り直しガイドラインを自動生成
透かして塗り込むだけで良くなり凄く楽になった…
 そしていよいよ抽出した頂点差分を使いアニメーションデータ化
なんだかおかしい感じはあるが
一発ポンの未調整でここまでできるなら随分と良いだろう
他のキャラクターでも上手く行くか色々試してみよう
そしていよいよ抽出した頂点差分を使いアニメーションデータ化
なんだかおかしい感じはあるが
一発ポンの未調整でここまでできるなら随分と良いだろう
他のキャラクターでも上手く行くか色々試してみよう
 タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
純粋なイラスト検知ではまぁまぁの精度。
そもそもPose Landmarkerは実写学習だから仕方ない。
しかし実写で認識するのであれば、AIで実写に変換すれば良いとも言える
キャプチャには実写、素材はイラストと分ければ良い。
Spineならそれができる…
タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
純粋なイラスト検知ではまぁまぁの精度。
そもそもPose Landmarkerは実写学習だから仕方ない。
しかし実写で認識するのであれば、AIで実写に変換すれば良いとも言える
キャプチャには実写、素材はイラストと分ければ良い。
Spineならそれができる…
 大き目の画像でも抽出できた
大き目の画像でも抽出できた
AIと対話するのにいちいちWEBツール(DEEPLなど)を通していたが手間を減らす為に内部でAI経由させる事を思いつく。 ComfyUIにはOllamaのカスタムノードがあるのでこれを使い 実行時に日本語文章からLLMを通じ自動プロンプト生成して実行するという流れにした。 すばらしい
なによりもまずSpineモデルの上手な作り方を知って居るかどうかが根底にある事を実感した。 Spineを勉強せねば… というわけで何が違和感の正体か調査と実験をしていた。 クオリティの高いSpineを作る為の解説を見たところ2.5Dを意識したモデルづくり 特に中間ボーンによる体の捻りが重要であることが分かった。

 腕や足に合わせて体も一緒に動くような作りのテスト
物理揺れモノ(自動制御)の動作確認
それらしくはなってきたか。
しかし服を着ていない方が繋ぎ目を隠せないためごまかしが効かず高難易度であることもわかった。。。
腕や足に合わせて体も一緒に動くような作りのテスト
物理揺れモノ(自動制御)の動作確認
それらしくはなってきたか。
しかし服を着ていない方が繋ぎ目を隠せないためごまかしが効かず高難易度であることもわかった。。。
 適当に画像ぶっこんでモーション抽出&Spine再生
適当に画像ぶっこんでモーション抽出&Spine再生
獣人化させると人体検出精度が下がった。そりゃそうか。
 拡張オプションとして猫耳ボーンや尻尾ボーン、羽生成もできるようにしていた。
拡張オプションとして猫耳ボーンや尻尾ボーン、羽生成もできるようにしていた。
しかし人体骨格トラッキングでアニメーション化するにも 本来検出できない人体外パーツを手打ち作業で合成するのは大変なのでどうにかできないものかと考えていたところ WARP_GATEの作成研究で使っていたオブジェクトトラッキングの併用を閃く。 オブジェクトトラッキングは記憶した画像の変化量を見るものだが これを獣人パーツに適用すれば変化量を追跡できるのではないだろうかと。
 結果は人外パーツの自動認識に成功(アニメーションデータにできるということ)
しかしトラッキングモデルでは人体の誤検出が発生する/(^o^)\
うまくやるには骨格検出との併用をせねばならんが、前述の通り獣人画像では骨格の誤検知が起こる
まぁ構想はひねり出してあり
これまたAIのSegment Anything Model(SAM)でセグメント抽出を組み合わせて行けば骨格検出へ繋げられるのではないかと。
結果は人外パーツの自動認識に成功(アニメーションデータにできるということ)
しかしトラッキングモデルでは人体の誤検出が発生する/(^o^)\
うまくやるには骨格検出との併用をせねばならんが、前述の通り獣人画像では骨格の誤検知が起こる
まぁ構想はひねり出してあり
これまたAIのSegment Anything Model(SAM)でセグメント抽出を組み合わせて行けば骨格検出へ繋げられるのではないかと。
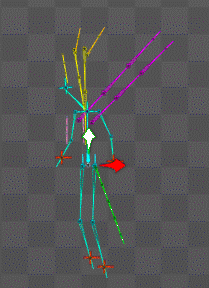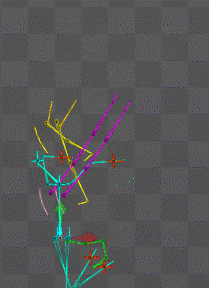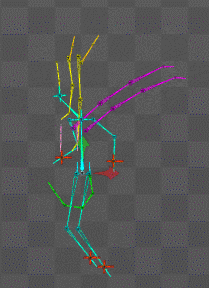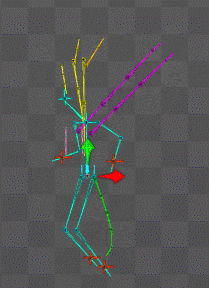 ボーンは物理設定にしておけば勝手にしなってくれるので喜ばしい
AI機械学習総動員で挑むものの
時間が足りない(無職の癖に)とはこれ如何に。
ボーンは物理設定にしておけば勝手にしなってくれるので喜ばしい
AI機械学習総動員で挑むものの
時間が足りない(無職の癖に)とはこれ如何に。
ボーンデータを元にSAM検出を行う
 見事な検出精度。
そして、人間化
見事な検出精度。
そして、人間化
 獣耳を黒くしているのは、ただくり抜いただけだと酷い骨格検出精度になった為
(陥没していると人の頭と認識されなかったようだ)
帽子を被っているかのようにごまかしたら精度アップ…
獣耳を黒くしているのは、ただくり抜いただけだと酷い骨格検出精度になった為
(陥没していると人の頭と認識されなかったようだ)
帽子を被っているかのようにごまかしたら精度アップ…
 と思いきや、何故か検出精度が悪化する。
(顔を肩にされている)
と思いきや、何故か検出精度が悪化する。
(顔を肩にされている)
細かいところで見るとくり抜きすぎている部分もあるし髪の色が肌の色に似ているのもあるのかもしれない。 かといって転生前の人型の時は検出できていたので前者の恐れが強い。 まぁとにかく認識出来れば大丈夫だろう… みんな大好きi2iも組み合わせてそれっぽくしてもらう
 AIイラスト変換特有の別人化したり髪とか服とかチラチラするが
AIイラスト変換特有の別人化したり髪とか服とかチラチラするが
 案ずるな、私は君たちのガワには興味が無いんだ
(骨しか見ていないマッドサイエンティスト)
…いい感じに骨格が抽出出来ているようだ。
獣人だろうと天使だろうと堕天&転生させて骨を拾うというまさに黒魔術。
案ずるな、私は君たちのガワには興味が無いんだ
(骨しか見ていないマッドサイエンティスト)
…いい感じに骨格が抽出出来ているようだ。
獣人だろうと天使だろうと堕天&転生させて骨を拾うというまさに黒魔術。
 オブジェクトトラッキングの弱点は手足の交差にある
(右足と左足がくっついてしまう)
オブジェクトトラッキングの弱点は手足の交差にある
(右足と左足がくっついてしまう)
 骨格推論との融合…
成功だ。
骨格推論との融合…
成功だ。
見ての通り羽や尻尾、髪の毛までもが直線最短距離による分割なので 物理で揺らしてみるとわかるがとにかく見栄えが悪い ボーンだけで見ればそうでもないがメッシュとなると酷い物なのだ 今回はここに手を入れる
 調べてみるとOpenCVのdistanceTransformが使えそうだったのでこれを使い画像から外側までの距離をマップ化する
これだけでは尻尾のような弧を描いている画像にどうも弱かったので
画像を煮詰めて、完全な線となった状態にして重心を割り出す
割り出した重心線に自動ロボット制御とかでおなじみのライントレースを応用して重心に沿ったボーン位置を確定させる
調べてみるとOpenCVのdistanceTransformが使えそうだったのでこれを使い画像から外側までの距離をマップ化する
これだけでは尻尾のような弧を描いている画像にどうも弱かったので
画像を煮詰めて、完全な線となった状態にして重心を割り出す
割り出した重心線に自動ロボット制御とかでおなじみのライントレースを応用して重心に沿ったボーン位置を確定させる

 こちらも成功
ボーンが画像に吸着できるようになった
こちらも成功
ボーンが画像に吸着できるようになった
胸のボーンを忘れていたので同様に重心トレースを施す 揺れモノパラメーターやメッシュのバインド比率計算も調整
 正しい重心とボーン配置によって一段階上の揺れ具合にできたのではなかろうか
正しい重心とボーン配置によって一段階上の揺れ具合にできたのではなかろうか
 骨格検出はどんなに精度が高くても肩の上が検出される(これが仕様)
実際にSpineで使用したいポイントはパーツが一回転しても後ろ側があまり見えない地点、つまり重心にある。
骨格検出はどんなに精度が高くても肩の上が検出される(これが仕様)
実際にSpineで使用したいポイントはパーツが一回転しても後ろ側があまり見えない地点、つまり重心にある。

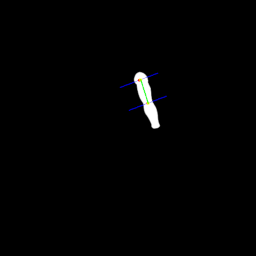
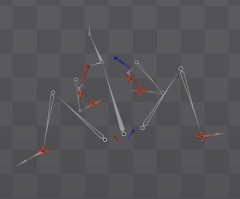
 モデル生成の段階ではこのズレている骨格情報では使い物にならない為改良を加える。
今までは任意のポイントをARマーカーを合成することで補正していたボーンポイントだが
目視ではやはりズレる為ここにさらに重心割り出しロジックを当てはめて吸着させパーツの精度を上げる試みをする。
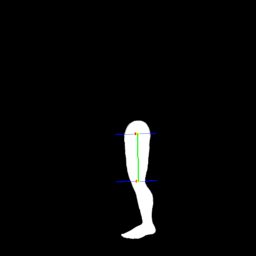
こういった地味な調整が続く。
(赤い点が目視よる無理矢理補正ポイント、緑が割り出された重心線)
しばらくはオートメーション化の為の調整が続く
実に眠くなる
モデル生成の段階ではこのズレている骨格情報では使い物にならない為改良を加える。
今までは任意のポイントをARマーカーを合成することで補正していたボーンポイントだが
目視ではやはりズレる為ここにさらに重心割り出しロジックを当てはめて吸着させパーツの精度を上げる試みをする。
こういった地味な調整が続く。
(赤い点が目視よる無理矢理補正ポイント、緑が割り出された重心線)
しばらくはオートメーション化の為の調整が続く
実に眠くなる
他にもモーションキャプを見つけたのでメモ https://github.com/freemocap/freemocap
アニメーション合成にも着手

 中間ボーン追加に物理パラの調整
(物理パラはどういう計算すればいいのか想像つかないのでとりあえず決め打ち)
テクスチャチェンジも追加した
顔とか手とか、本当は左手もグーにしたかったが時間の兼ね合いで妥協
それなりに形になってきたか?
中間ボーン追加に物理パラの調整
(物理パラはどういう計算すればいいのか想像つかないのでとりあえず決め打ち)
テクスチャチェンジも追加した
顔とか手とか、本当は左手もグーにしたかったが時間の兼ね合いで妥協
それなりに形になってきたか?
 歩きモーションは人体状態からモーション抽出できたので転生不要
歩きモーションは人体状態からモーション抽出できたので転生不要
 走りモーションは実験込みで羽と尻尾有画像から転生させているので若干遠回り
(デバッグ用に転生前素材との合成)
細かく見れば下半身の捻りが課題だが、Spine素人には今が限界。
まだまだ勉強せねば…(上半身と下半身のパーツを分ければできるか?)
走りモーションは実験込みで羽と尻尾有画像から転生させているので若干遠回り
(デバッグ用に転生前素材との合成)
細かく見れば下半身の捻りが課題だが、Spine素人には今が限界。
まだまだ勉強せねば…(上半身と下半身のパーツを分ければできるか?)
上半身と下半身のパーツを分けたりパラメーターの調整をしたりと地味な調整が続いていた。 Spineのバージョン差異もあり、なかなか手間取ったが遂にここまで辿り着くことが出来た。
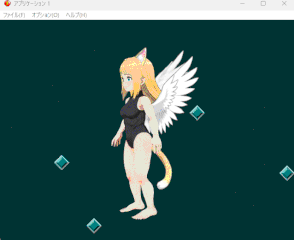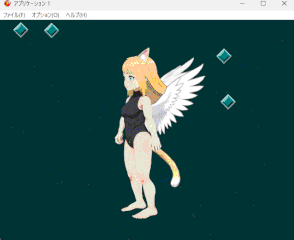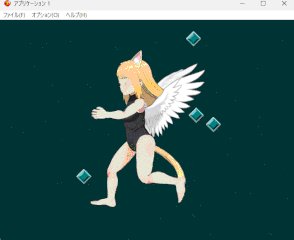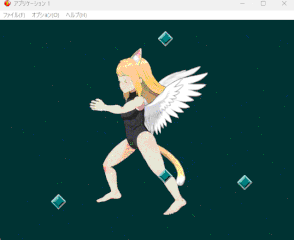 しかしまあきっと一発でSpine出力できるようなAIも出てくることだろう
〜完〜
〜続〜
もはやSpineモデル生成プログラムはほぼ完成と見込んでいたが
ついでにひとつ上の表現力を実装しようと思いSpineExtensionにも手を入れる
ここから先はサドンデスでありもはや生成AI関係無し!
しかしまあきっと一発でSpine出力できるようなAIも出てくることだろう
〜完〜
〜続〜
もはやSpineモデル生成プログラムはほぼ完成と見込んでいたが
ついでにひとつ上の表現力を実装しようと思いSpineExtensionにも手を入れる
ここから先はサドンデスでありもはや生成AI関係無し!
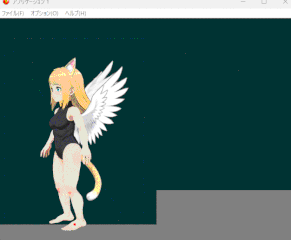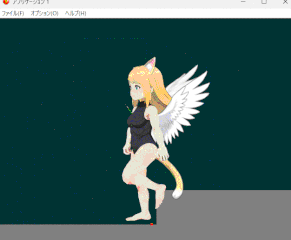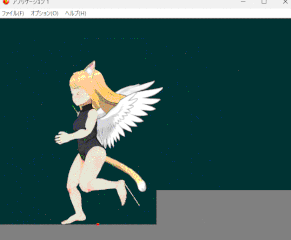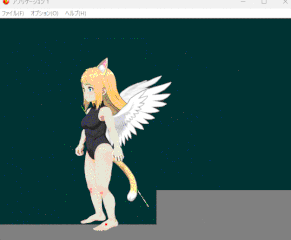 IKやボーンをアニメーション中でも操作できるように改良しつつ
いわゆる地面に沿った手足を実装できるようにした。
・・・つもりだがモデルの足の構造が悪くイマイチな結果となった。
接地の為につま先や踵を含めた足のボーンを追加せねばならんようだ…
IKやボーンをアニメーション中でも操作できるように改良しつつ
いわゆる地面に沿った手足を実装できるようにした。
・・・つもりだがモデルの足の構造が悪くイマイチな結果となった。
接地の為につま先や踵を含めた足のボーンを追加せねばならんようだ…
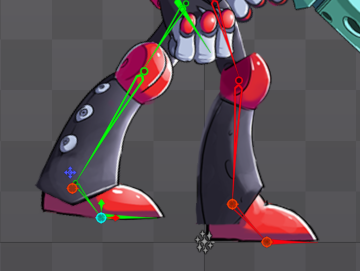 公式サンプルを参考に見るとベタ足のボーンを末端に入れるのが良さそうだ。
上手く行ったらSpineExtensionもバージョンアップ作業となる。
まだまだやる事が山積みだ…。
公式サンプルを参考に見るとベタ足のボーンを末端に入れるのが良さそうだ。
上手く行ったらSpineExtensionもバージョンアップ作業となる。
まだまだやる事が山積みだ…。
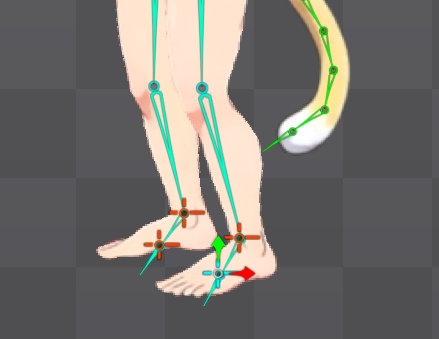 ボーンの自動生成構造を公式水準に拡張することに成功
ボーンの自動生成構造を公式水準に拡張することに成功
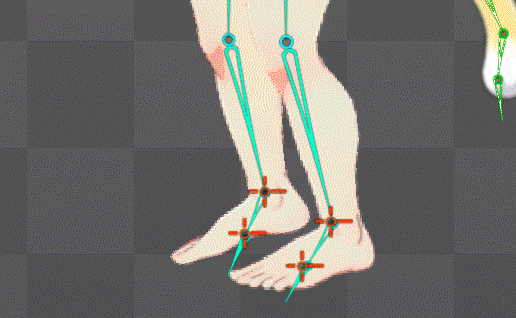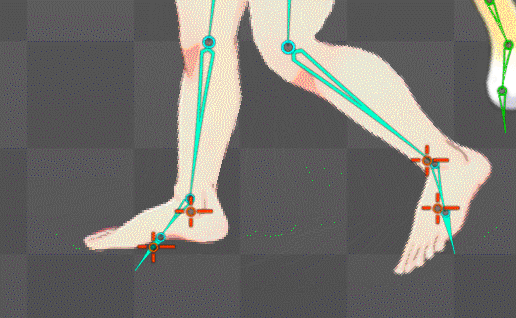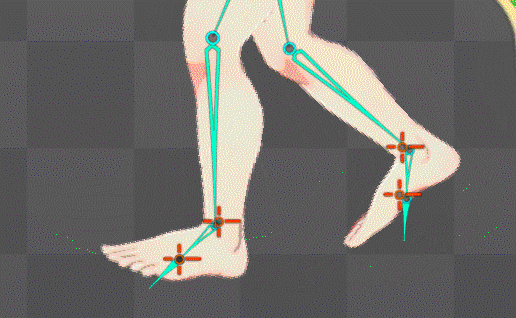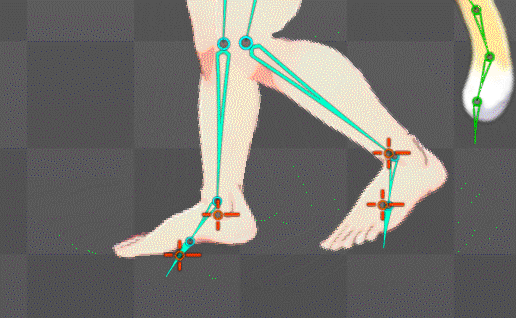
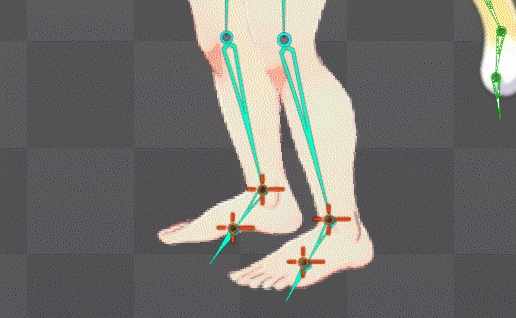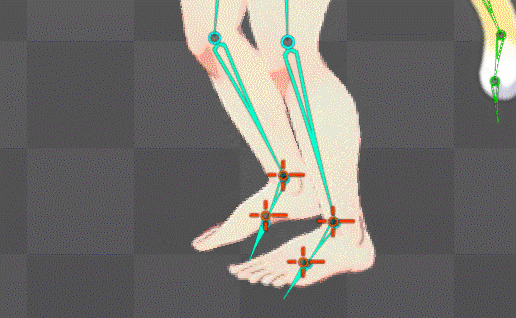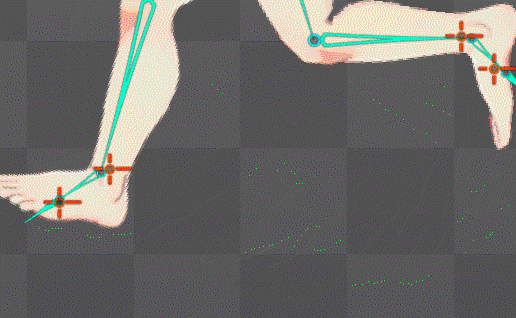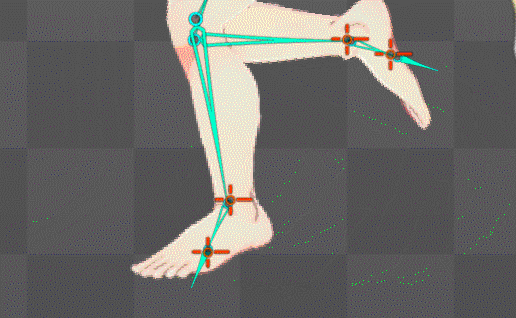 これにより足の裏の地点にあるボーンが基準となり足首もIK化したのでめり込み制御も直ぐに可能になったはず
これにより足の裏の地点にあるボーンが基準となり足首もIK化したのでめり込み制御も直ぐに可能になったはず
しかし恐ろしい事に最新のCFでAndroidRuntimeがいつのまにかかなり拡張されていたようで 現在公開しているSpineのAndroidが動かなくなっていた。 対応せねば…(対応した!)
ゲームを作るにしてもまだまだパーツが足りないことに気づく。 とりあえずアクション向けキャラクター生成プログラムは一応完成したとして一旦離れる。 再度生成沼へ戻ることにした。 そして次は会話シーン等のバストアップモデルの自動生成に挑む。
 まずは適当に正面を向かせてAI動画化する。
今でもボタン一つでこういうのが作れるのが驚きだが、これをこのまま使うとえらいことになる(容量が)
生成動画は狙った動きをプロンプトで作る事が簡単に出来るとは言えないのも大きな懸念点だ。
しかし融合研がゴールにしているのはボーン抽出である。
いっそWEBCAMを通じて自分が演じても良いが、骨格までは合わないのでそこから更に転生させる必要もあるだろう…
(この計画の行きつく先はSpine抽出なので元画像は別に生成画像である必要も無い)
まずは適当に正面を向かせてAI動画化する。
今でもボタン一つでこういうのが作れるのが驚きだが、これをこのまま使うとえらいことになる(容量が)
生成動画は狙った動きをプロンプトで作る事が簡単に出来るとは言えないのも大きな懸念点だ。
しかし融合研がゴールにしているのはボーン抽出である。
いっそWEBCAMを通じて自分が演じても良いが、骨格までは合わないのでそこから更に転生させる必要もあるだろう…
(この計画の行きつく先はSpine抽出なので元画像は別に生成画像である必要も無い)
 そして勿論静止画としてみると動きのある細部はバッチリ破綻している
そして勿論静止画としてみると動きのある細部はバッチリ破綻している
ここからおなじみgoogle大先生による検出AIを頼る。 https://ai.google.dev/edge/mediapipe/solutions/vision/face_landmarker
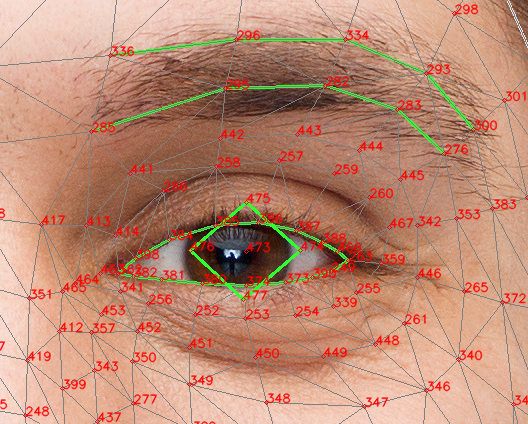 今回試していくのは顔のランドマークに特化したAI検出で
これもまたボーンに落とし込み差分を頂戴すればアニメーションデータも手に入るだろうという寸法である。
この手の方向ではフェイスリグとかVTuberだとか沢山の先輩方もいることだろう。
…いざ検出
今回試していくのは顔のランドマークに特化したAI検出で
これもまたボーンに落とし込み差分を頂戴すればアニメーションデータも手に入るだろうという寸法である。
この手の方向ではフェイスリグとかVTuberだとか沢山の先輩方もいることだろう。
…いざ検出
 なんの成果も!!得られませんでした!!
※進撃の巨人 諫山創/講談社
骨格モデルとは異なり、獣人どころか人間状態でも全く検出することが出来なかった。
…まさに人間の顔のみで微細な動きを学習した特化モデルである事がわかる。
なんの成果も!!得られませんでした!!
※進撃の巨人 諫山創/講談社
骨格モデルとは異なり、獣人どころか人間状態でも全く検出することが出来なかった。
…まさに人間の顔のみで微細な動きを学習した特化モデルである事がわかる。
AIで困ったらAIに聞く ということで…聞いてみると アニメ系に特化した学習モデルもあるという Anime Face Detector https://github.com/hysts/anime-face-detector dlibのアニメ顔学習済みモデル等、 類似の検出モデルも多数存在することがわかった。 融合研の冒険はまだ始まったばかりだ!(完)
本日はあまり上手く行かない日に終わった。 Anime Face Detectorは環境構築が特殊で難儀しかけたので一旦白紙。 環境依存が多いライブラリを使用しているらしく現行環境を変更してまでのインストールが必要になり難しかった。 dlib学習モデルもなにやら上手く行かずに終わった。 ついでにセミナーも失敗する(ここでは関係ない話題) そんな日もあるさ!
転生術による検出の検証
 何もないよりは検出できるようになったが目の幅が足りない。
実写学習モデルがベースなのでリアル人間サイズに検出されているようだ。
まぁ誤検出とも言える状態である。
これを全て手直しするのはキツイので無しとする。
Anime Face Detectorの導入を優先する事にした。
環境依存があってどうしようもなかったのでfaceボーンを抽出するだけの仮想環境を作成し
抽出を中間ファイル化し後で合成できるように仕様を変更する
何もないよりは検出できるようになったが目の幅が足りない。
実写学習モデルがベースなのでリアル人間サイズに検出されているようだ。
まぁ誤検出とも言える状態である。
これを全て手直しするのはキツイので無しとする。
Anime Face Detectorの導入を優先する事にした。
環境依存があってどうしようもなかったのでfaceボーンを抽出するだけの仮想環境を作成し
抽出を中間ファイル化し後で合成できるように仕様を変更する
頑張ってAnime Face Detectorを導入した 動作環境に必要なモジュールの相性が悪いので複数の仮想環境をはしごしての実装 しかし、頑張った甲斐のある検出精度となる
 目玉の位置はAnime Faceでは取得できない為、別のAI検出を組み合わせて合成する
こっちはまだ実際取れているのかよくわからんので運用次第となるが
いずれにしても転生せずに取れるようになったのも良い
目玉の位置はAnime Faceでは取得できない為、別のAI検出を組み合わせて合成する
こっちはまだ実際取れているのかよくわからんので運用次第となるが
いずれにしても転生せずに取れるようになったのも良い
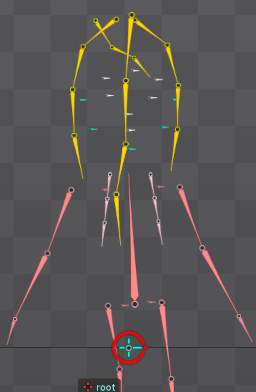 ざっくり抽出
輪郭にボーンがあれば多少の向き変化も2.5D的に対応できそうな気はするが
まぶたとかもどのくらいあればいいんだろう
Live2Dはデフォームベースでボーンはなかったのでこのあたりが割と未知数
なんだかんだで実験ソースが大掛かりになって煩雑になってしまったので
一度作り直しレベルで洗練&改修中。
脳内に設計図があるうちに一気に進めてしまいたいが
忍び寄る就活認定日に震え上がる日々
ざっくり抽出
輪郭にボーンがあれば多少の向き変化も2.5D的に対応できそうな気はするが
まぶたとかもどのくらいあればいいんだろう
Live2Dはデフォームベースでボーンはなかったのでこのあたりが割と未知数
なんだかんだで実験ソースが大掛かりになって煩雑になってしまったので
一度作り直しレベルで洗練&改修中。
脳内に設計図があるうちに一気に進めてしまいたいが
忍び寄る就活認定日に震え上がる日々
 リファクタリング中。
これまでの実験からどのように自動化するのが良いか勘所を掴んできたので再度ゼロからの再構築。
処理を細分化し検出機構と構築機構を分離しモジュール化する。
まだまだ動くに満たない。(あちこちズレてる)
引き続きバストアップモデルの検出とテンプレ化を進める。
表情コントロールのボーンが大変だ…
アクションゲーム向けはこのままフェイスボーン関係を一掃し
フェイスパーツは全て顔テクスチャとして画像合成すれば動かせるようにする想定
先は長そうだ…
リファクタリング中。
これまでの実験からどのように自動化するのが良いか勘所を掴んできたので再度ゼロからの再構築。
処理を細分化し検出機構と構築機構を分離しモジュール化する。
まだまだ動くに満たない。(あちこちズレてる)
引き続きバストアップモデルの検出とテンプレ化を進める。
表情コントロールのボーンが大変だ…
アクションゲーム向けはこのままフェイスボーン関係を一掃し
フェイスパーツは全て顔テクスチャとして画像合成すれば動かせるようにする想定
先は長そうだ…
完全な初動ミス。 バストアップモデルという事で元画像を拡大したが 手が見切れている事によって重心計算が破綻していたようだ… とりあえず膝くらいまではある状態で作り直す事に。
モデルの作り直し…
 そしてモデルの検出工程をやり直していると気が付いた。
これはもしかして検出デプスにボーンからSAMすれば(謎語w)
羽や尻尾の堕天転生と同じ処理の応用で
切り出しパーツも殆ど自動分解できるんじゃないか…?
そしてモデルの検出工程をやり直していると気が付いた。
これはもしかして検出デプスにボーンからSAMすれば(謎語w)
羽や尻尾の堕天転生と同じ処理の応用で
切り出しパーツも殆ど自動分解できるんじゃないか…?


 髪の分解・腕の分解・胸の分解
髪の分解・腕の分解・胸の分解
8〜9割成功ってところか。
 AI特有の塗りムラか、若干欠けている部分もあるが最後に手直すれば良いので
初期モデル配置のパーツ別け作業は大幅短縮といえる。
どのみち回転パーツの整合性合わせ等で手を入れて行く必要はある。
画像コンバート&合成して画像未処理でここまで作ることが出来た。
しかしアクション用は実験含めてもあり顔パーツなど端折れるところは端折り比較的小規模に漕ぎつけたが
バストアップモデルはまだまだ手を入れる箇所が多く想像以上に巨大だった。
そりゃ専任デザイナー要るわなぁ。
AI特有の塗りムラか、若干欠けている部分もあるが最後に手直すれば良いので
初期モデル配置のパーツ別け作業は大幅短縮といえる。
どのみち回転パーツの整合性合わせ等で手を入れて行く必要はある。
画像コンバート&合成して画像未処理でここまで作ることが出来た。
しかしアクション用は実験含めてもあり顔パーツなど端折れるところは端折り比較的小規模に漕ぎつけたが
バストアップモデルはまだまだ手を入れる箇所が多く想像以上に巨大だった。
そりゃ専任デザイナー要るわなぁ。
顔パーツの自動化難し過ぎ。
失敗と調整の繰り返し。 出口はまだ見えず。 難易度的に顔パーツがラスボスだ…

 元絵を見て判る通り、腕をカメラ方向に経由する動きが鬼門だった。
IK適用では必ず左右に曲がる事になる為、エクストラ処理としてIKを外してのトレース。
目のクリッピング処理、口のクリッピング処理と、手を入れる箇所も多かった。
全体のクオリティでは描画順位といい、まつげのウエイト処理といいまだ手が回っていない部分も多い。
手も指先検知とかで反転するようにもしたい。
ここまでをみるとそれなりのところまでは行けそうだが、それなりで終わりそうな気もする。(十分か?)
しかし次の手は既に考えてある。
いわゆるパッチ法だ。
変化差分の最小切り抜き画像をパラパラ表示にしてごり押す方法である。
スプライトシートだとキャラクター全体をパラパラ表示するので容量が凄い事になるが
パッチ法なら変化差分のみの保存なので容量が減るのだ。
まぁいっそそれだけで良いような気すらしてくるが。
元絵を見て判る通り、腕をカメラ方向に経由する動きが鬼門だった。
IK適用では必ず左右に曲がる事になる為、エクストラ処理としてIKを外してのトレース。
目のクリッピング処理、口のクリッピング処理と、手を入れる箇所も多かった。
全体のクオリティでは描画順位といい、まつげのウエイト処理といいまだ手が回っていない部分も多い。
手も指先検知とかで反転するようにもしたい。
ここまでをみるとそれなりのところまでは行けそうだが、それなりで終わりそうな気もする。(十分か?)
しかし次の手は既に考えてある。
いわゆるパッチ法だ。
変化差分の最小切り抜き画像をパラパラ表示にしてごり押す方法である。
スプライトシートだとキャラクター全体をパラパラ表示するので容量が凄い事になるが
パッチ法なら変化差分のみの保存なので容量が減るのだ。
まぁいっそそれだけで良いような気すらしてくるが。
変化差分切り抜きロジックの作成 まずはボーンを軸にSAM2モデル(AI)を適用し手のトラッキングを行わせる コマの切り替わり検知はボーンの移動量とマスクピクセルの変化量を基準にしている
 で、マスク箇所そのまま切り抜いて使用しても座標がぶっとぶので正規化を行い原点へ合わせる
ついでに元絵も原点へ合わせマスクの誤検知に備えておく。
こうしておけば透かしレイヤーで楽に塗りつぶせるという寸法だ
で、マスク箇所そのまま切り抜いて使用しても座標がぶっとぶので正規化を行い原点へ合わせる
ついでに元絵も原点へ合わせマスクの誤検知に備えておく。
こうしておけば透かしレイヤーで楽に塗りつぶせるという寸法だ
 これまでの経験上AIで完璧を目指すには無駄が多くパラメーター一つ変えるだけで無に帰す事すらある為
AIでは完全な物を作る事が出来ないという前提にし、人間のサポートまでを工程に含めた全体で考えたほうが早いという結論に至っている…。
検知タイミングをそのまま手の画像の切り替わりに使う
これまでの経験上AIで完璧を目指すには無駄が多くパラメーター一つ変えるだけで無に帰す事すらある為
AIでは完全な物を作る事が出来ないという前提にし、人間のサポートまでを工程に含めた全体で考えたほうが早いという結論に至っている…。
検知タイミングをそのまま手の画像の切り替わりに使う
 アニメーションが若干ゆっくりなので少し違和感があるかもしれないが、切り替わりは理屈上同等だ
(手が透けている誤検知マスク分は塗りつぶすのもめんどくさいのでやっていないだけです)
これはスケルタルアニメーションでは表現しづらい複雑なアニメを補完するテクニックの一つとなるはずだ
次は腕と胸の境界を越えさせるZ-ORDERの突破方法を考えねば…
(現状は腕が前面にあるが上腕は胸の奥になければならない、そして入れ替わる)
アニメーションが若干ゆっくりなので少し違和感があるかもしれないが、切り替わりは理屈上同等だ
(手が透けている誤検知マスク分は塗りつぶすのもめんどくさいのでやっていないだけです)
これはスケルタルアニメーションでは表現しづらい複雑なアニメを補完するテクニックの一つとなるはずだ
次は腕と胸の境界を越えさせるZ-ORDERの突破方法を考えねば…
(現状は腕が前面にあるが上腕は胸の奥になければならない、そして入れ替わる)
Z-ORDERはパーツの重なり検知をすれば良いので割と直ぐ上手く行った。
 しかし、根本部分にある検知誤差がどうしようもなく高い壁だなあ…
しかし、根本部分にある検知誤差がどうしようもなく高い壁だなあ…
 (エディタ上で直せばすぐ終わる話ではあるが)
(エディタ上で直せばすぐ終わる話ではあるが)
誤差縮小に向けて、他のAI用検出モデルを調べていた。 動作環境準備から行う必要があり時間が掛かるのが大変だったが hrnet,vit,yoroそしてmediapipeと様々なパターンを実装し見比べたところ ベースとして使用していたmediapipeは元々モバイル向けということもあり 軽量だが精度がそこそこという事で元々誤差が大きいモデルだった。 vit,yoroは精度は高かったが、検出点に手先が無く情報が少し足りなかった。 hrnetは手先まで取れたが揺らぎが強く駄目そうだった。 (絵柄の特色が異なる画像出力モデルと同じように検出モデルも同じように沢山ある) 現在の結論としてはvitのcoco_wholebodyモデルに落ち着いた。 だが、これはこれでバストアップ以下、映っていない座標の推論がほぼ乱数なのでどうにも粗ぶってしまうのが少々引っかかる
手書きベースイラストを動画化し、雑に変換。


 タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
ちゃんと指定しきれてない髪が物理で明後日に動いちまってる!
(キャプチャミスってコマも足りてない)
今の感じだといっそアクションフィギュアとムービーで割り切って考えてしまうのが良いのかもしれん
うーんまだまだだ
タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
ちゃんと指定しきれてない髪が物理で明後日に動いちまってる!
(キャプチャミスってコマも足りてない)
今の感じだといっそアクションフィギュアとムービーで割り切って考えてしまうのが良いのかもしれん
うーんまだまだだ

 タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
Spine構造化と取り込みスキームは大体できたが(たぶん)
次の問題は書かれていない部分を如何にして補完するかだな…
知恵を絞らねば
ボーン情報だけで考えるのもありか。
重なっている片方の腕を移動させボーンをOPENPOSEとして出力変換し
AIに描かせてみれば姿勢そのままで描いてくれそうな気もする。
タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
Spine構造化と取り込みスキームは大体できたが(たぶん)
次の問題は書かれていない部分を如何にして補完するかだな…
知恵を絞らねば
ボーン情報だけで考えるのもありか。
重なっている片方の腕を移動させボーンをOPENPOSEとして出力変換し
AIに描かせてみれば姿勢そのままで描いてくれそうな気もする。
 ベース絵とボーンの透かし
ベース絵とボーンの透かし
 ボーンを動かしてリペイント
破綻は激しいが狙いである右腕は無事に頂けた
ボーンを動かしてリペイント
破綻は激しいが狙いである右腕は無事に頂けた
 ボーン透かしをミスったが同じ方法で左腕を頂けた
破綻を気にすると難しいが必要部位だけなら
ボーンを制すれば制する事が出来るようだ
タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
ボーン透かしをミスったが同じ方法で左腕を頂けた
破綻を気にすると難しいが必要部位だけなら
ボーンを制すれば制する事が出来るようだ
タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
AやTポーズからなら切り出しも含め大体いけるが 複雑な姿勢は検知自体に失敗する可能性が高い。(AI特性の問題) 人の手の介在によって対応自体は出来るが そこを詰めるのは合理的ではなさそうだ 単純にまずAIでAやTにポーズを変更してから取り込み 任意の姿勢に持って行った方が早そうだ。
別の画像での実験
 何パターンかの検知AI(hrnet,vit,yoro,mediapip)を使ってみたものの芳しくはない。
前回の画像もそうだが、誤検知の元はファー(毛皮)にあるようだ。
姿勢自体も難しいと思うがこのしゃがみファーは酷い有様だ。
何パターンかの検知AI(hrnet,vit,yoro,mediapip)を使ってみたものの芳しくはない。
前回の画像もそうだが、誤検知の元はファー(毛皮)にあるようだ。
姿勢自体も難しいと思うがこのしゃがみファーは酷い有様だ。
あれこれ試してみたところ 体のラインを隠している服と姿勢が問題のようだった。 AIプロンプトによるお着替えを施し、i2iの堕天変換を行いボーン抽出を通す。
 多少のごみが発生しているがボーン抽出が出来れば良いので細部は気にしない。
問題は元絵との動きの剥離だが
多少のごみが発生しているがボーン抽出が出来れば良いので細部は気にしない。
問題は元絵との動きの剥離だが
 OpenPoseの抽出と、WanのFunControlによって服を着ている状態で同じ動きをトレースさせる。
OpenPoseの抽出と、WanのFunControlによって服を着ている状態で同じ動きをトレースさせる。
 タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
全体で見ると細部の破綻もあるがSpine切り出しなら関係ない
これで手のパラパラアニメーション部分などドラスティックな形状変化の必要パーツは大体揃う。
あとはそれぞれ必要箇所を融合して行けばおそらくできる…はず
タイトル:[ジュエルセイバーFREE]
URL:[http://www.jewel-s.jp/]
全体で見ると細部の破綻もあるがSpine切り出しなら関係ない
これで手のパラパラアニメーション部分などドラスティックな形状変化の必要パーツは大体揃う。
あとはそれぞれ必要箇所を融合して行けばおそらくできる…はず
試せば試す程に進めば進むほどに問題は起こる 自動画像分解のAIであるsee_throughで誤検知によるパーツの検知ロスが発生してしまった
 折りたたまれた足の先は無い物として扱われてしまっている
検知できないものは仕方がないので方法を考える
ここにロボットアーム操作とかで出てくるようなファジイ理論を充てる
大層な事のようにそれらしく言ってみたが単純に取りこぼしをどうするかというだけであるが
折りたたまれた足の先は無い物として扱われてしまっている
検知できないものは仕方がないので方法を考える
ここにロボットアーム操作とかで出てくるようなファジイ理論を充てる
大層な事のようにそれらしく言ってみたが単純に取りこぼしをどうするかというだけであるが
 無事補完
フィジカルAIといい今後はこういった検知漏れの対策が課題として続くのだろう
無事補完
フィジカルAIといい今後はこういった検知漏れの対策が課題として続くのだろう
猫耳帽子の回転処理やらファーやら AI検知が出来ない物体のボーンに対する(身に着けている物への検知AIはまだ無い) 検出&アニメーション動作に合わせた自動変形策を練っていた 施策と破棄を繰り返しをしていたがAIを活用してもどうにもイマイチ足りない物しかできなかった。 勿論これは指示が悪いだけなのだろうが 概要を含めた総合的指示ではどうにもやっぱりうまくいかない(3次元計算を含めると尚更) が、詳細に設計を定義した上で細かく指示するとそれなりに上手く行く感じにはなる。
 なんというかAIコーディングも結局は他言語翻訳と変わりないんだなと思えている。
まだまだ功夫が足りないようだ…
(つまり設計力を伸ばせるCF2.5は最高のツールである)
なんというかAIコーディングも結局は他言語翻訳と変わりないんだなと思えている。
まだまだ功夫が足りないようだ…
(つまり設計力を伸ばせるCF2.5は最高のツールである)

 検知ノイズやら回転基点のズレやらでうまくいかない
試みは徒労に終わる
検知ノイズやら回転基点のズレやらでうまくいかない
試みは徒労に終わる
何度もやり直し この手の物は妥協案や力技で無理矢理進むことが出来ないのが辛い所だ

 アルゴリズムを練り直してひとまずの水準に到達した、と思いたい。
アルゴリズムを練り直してひとまずの水準に到達した、と思いたい。
切り出しと合成スキームに流す
 転生抽出の影響で手のボーンポジションと足のボーンポジションにズレがあるが、まあ許容範囲
とりあえず上手く行ったとみていいが、この絵は難易度が高かった。
※表示順位は手動で入れ替えています
転生抽出の影響で手のボーンポジションと足のボーンポジションにズレがあるが、まあ許容範囲
とりあえず上手く行ったとみていいが、この絵は難易度が高かった。
※表示順位は手動で入れ替えています
誤検知が前提にあり完全な自動化は難しい為 中間データを生成し、それなりに簡単に調整できるようにする為の補助ツールをひたすら構築
例えばデプスマップを利用してSpineの表示順位もある程度ソートした状態を作った。
それでも!デプス情報通りに並べても親子の流れがあるボーンでは表示順位は正しくならないのだ
並び順や裏側パーツの精度をもっと高める為、 分解AIツールであるsee_throughの原理を調べたり補助ツールをひたすら作っていた。 裏パーツの書き足しのキモ部分は検知した深度マップの予測をマスクとして使いインペイントすることにあるようだった(と仮定) つまり、同じような事をすれば近いことが出来るということ。
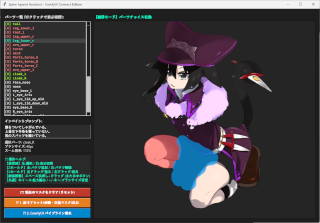
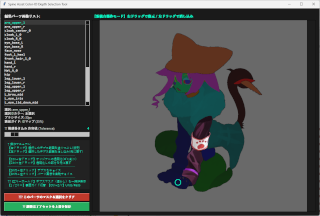 デプスマップをクリックして直ぐにインペイントできるツールとか
表示順を並び変えたり、パラパラアニメを入れ込むツール等…
(これはパーツをクリックするだけで表示を消せたり、そのまま上下キーで表示順位を変更するなど操作ストロークの短さに特化させてはいる)
諸々作るには作ったが、また少し良い方法も思いついてしまった。
デプスマップをクリックして直ぐにインペイントできるツールとか
表示順を並び変えたり、パラパラアニメを入れ込むツール等…
(これはパーツをクリックするだけで表示を消せたり、そのまま上下キーで表示順位を変更するなど操作ストロークの短さに特化させてはいる)
諸々作るには作ったが、また少し良い方法も思いついてしまった。
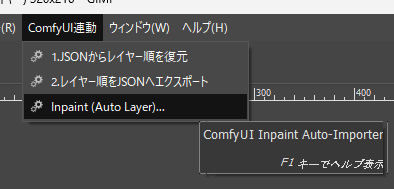 GIMPのプラグイン連動である。
選択範囲をインペイント、レイヤー順序をそのままボーン名と連動させSpineのスロット化といった感じだ
(元々SpineはPSDでレイヤーインポート可能だが、特殊な作り方をしているので合わせるのは難しい)
これで、厄介だった画像調整工程が短縮される…はず
GIMPのプラグイン連動である。
選択範囲をインペイント、レイヤー順序をそのままボーン名と連動させSpineのスロット化といった感じだ
(元々SpineはPSDでレイヤーインポート可能だが、特殊な作り方をしているので合わせるのは難しい)
これで、厄介だった画像調整工程が短縮される…はず
プラグインついでにMCPサ−バーの原理を調べた。 理論上CFのイベントもAIから直接エディタに書かせることができるのが判った。 やりようによってはアクションの配置とかもできるようになるはずだがこれは公式に対応してもらうのが一番だ… が、非公式グレーでもあえてやってみる融合スタイルも忘れない… それはさておき時間が出来たらイラストSpine化スキームを通しでテストしていく これはこれでどこまでいけるか
Spine化計画も進めてはいるものの成果を公表できるような画期的なものは無く ただただAIのゆらぎを補填するツールの制作ばかりである

アニメーション上のボーンの検知も トランスレートによるものかローテーションによるものかが検知できないケースが顕著になった。 これもまた課題である。 さらに親子パーツが多い場合、人の手によるイラストには同一パーツでも前後関係が複雑に交差しているケースがある。 基本的にAIイラストでこの構図は大体破綻するようなので見なかった構図だが 今回のイラストではAI的に検知不能の難しい状態になっている。
 (同一レイヤーで見ると、上部と下部で前後関係が入れ替わってしまっているのが判るだろう)
ひとつひとつ例外ケースで調整できるように潰していくしかない…
(同一レイヤーで見ると、上部と下部で前後関係が入れ替わってしまっているのが判るだろう)
ひとつひとつ例外ケースで調整できるように潰していくしかない…
パーツを分解して行くやり方ではどうも上手く行かないケースが発生した。
特に問題の個所は体のひねりである。
細かくしたパーツのボーン抽出だけではこれを表現ができ無かった為、別のアプローチが必要になった。
以前やったアレに近い事をバストアップモデルでもやらなければならないようだ。
あちらはアクション用モデルだったのでまだごまかしは効いたが
はたまたこちらでもできるだろうか。
勿論ある程度の方法はもう考えてある。
左右の目の高さや、左右の肩の高さを中心軸からの回転量として見なすとどうなるかである。
2.5Dに落とし込む為の中間検出といった所か。
長い道のりである。
進んではいるものの色々と難航中。 手ごたえが無い訳では無いのが救いではあるが 実に難しい。

 回転表現が必要なパーツを設定し
パーツ幅から均等にボーンを加えるロジックを追加したことで疑似的なパースペクティブを組み込むことが出来た。
これにより、首元のパーツや胴体のひねり表現が為されるようになった。
帽子はそもそも形状が変わるので変形ではうまくいっていない。
この手の動作が上手く行かないパーツは目視で動作パターンを指定しておく必要がある。
ウエイトによる変形とパラパラアニメーションのハイブリット化が必要だろう…
髪揺れは最初から最後まで物理に投げっぱなしだが
ボーンの始点をパースペクティブしないと髪の間に目があるという表現に追いついていないようだ。
振り返る顔はウエイト誤差による形状変化もありまだ見直す点もある。
特に顔の検出点は誤差ありのワールド座標なので、
首を傾げた動作により顔の子パーツとしてズレが発生しているというのもある。
ついでに元動画では尻尾が勝手に離れていたのには後から気が付く。
(ほんの一瞬だが指の数も変わっている)
実に難しいモデルだがもう一歩いけるだろうか。
回転表現が必要なパーツを設定し
パーツ幅から均等にボーンを加えるロジックを追加したことで疑似的なパースペクティブを組み込むことが出来た。
これにより、首元のパーツや胴体のひねり表現が為されるようになった。
帽子はそもそも形状が変わるので変形ではうまくいっていない。
この手の動作が上手く行かないパーツは目視で動作パターンを指定しておく必要がある。
ウエイトによる変形とパラパラアニメーションのハイブリット化が必要だろう…
髪揺れは最初から最後まで物理に投げっぱなしだが
ボーンの始点をパースペクティブしないと髪の間に目があるという表現に追いついていないようだ。
振り返る顔はウエイト誤差による形状変化もありまだ見直す点もある。
特に顔の検出点は誤差ありのワールド座標なので、
首を傾げた動作により顔の子パーツとしてズレが発生しているというのもある。
ついでに元動画では尻尾が勝手に離れていたのには後から気が付く。
(ほんの一瞬だが指の数も変わっている)
実に難しいモデルだがもう一歩いけるだろうか。